Chatbot
This assignment will focus on finetuning our previous GPT-2 pretrained language model to build a basic chatbot using the PERSONA dataset.
Getting Started
For this assignment, make sure the Huggingface Pytorch-Transformers package are installed as we will be continuing using it. The documentation for the related functions you may use in this assignment can be found here.
Stencil code (PyTorch) is available in the course directory at
The dataset for this assignment is as follows (from the PERSONA dataset):
PERSONA is a dataset for training chitchat conversations. The data is in txt, and is formatted as:
/course/cs1460/asgn/chatbot. You can copy this folder into your current directory by running (s)cp -r /course/cs1460/asgn/chatbot ./ (Replace the last argument with a different directory to copy the files to that directory.) The dataset for this assignment is as follows (from the PERSONA dataset):
PERSONA is a dataset for training chitchat conversations. The data is in txt, and is formatted as:
sentence_id your persona: ...
sentence_id partner's persona: ...
sentence_id prompt \t responseFinetuning GPT-2 Model
In this part you will fine-tune your GPT-2 model by training the pretrained model on the new dataset. Then test its performance by calculating the perplexity on the test dataset. The steps are as follows:
- Tokenize the train and test dataset using GPT-2's tokenizer. Add special tokens (Beginning of sentence, End of sentence, padding, separation token between prompt and response) to the pre-defined vocabulary.
- Load pretrained GPT-2 model and train it with the new dataset.
- Evaluate the perplexity of the fine-tuned model on the test set.
Interacting with the Fine-tuned model
In this part, you will write your own prompt to 'chat' with the pretrained model. Instead of teacher-forcing, we need to generate the response iteratively. The steps are:
If you freeze some parts of your model, you should be able to get really good performance with minimal training(Lee et al.). If you unfreeze the whole model and do further training, you should be able to get the same level of performance compared to fine-tuning all layers but use less computation time. If you implement freezing, we will give you some extra credit.
- Tokenize your prompt and add appropriate tokens.
- Pass the tokenized prompt into the fine-tuned model to generating the most probable next word by using top-k filtering (sorting by probability and zero-ing out the probabilities for anything below the k’th token).
- Concatenate the most probable word with the current input as the new input then feed it into the model again to repeat the last two steps iteratively.
- remove any meaningless tokens when printing out the response.
If you freeze some parts of your model, you should be able to get really good performance with minimal training(Lee et al.). If you unfreeze the whole model and do further training, you should be able to get the same level of performance compared to fine-tuning all layers but use less computation time. If you implement freezing, we will give you some extra credit.
Handin & Evaluation
Run
In your README, please note down:
As a sanity check, the model should have less than perplexity of 100. But if youwere unable to get good results from the models developed, further write down in your README:
If you were unable to get good results from the models developed, further write down in your README:
Going through these steps should hopefully help you identify the potential issues in your code, if any. Even if you were unable to find the issue in time, the report that you have created at this point would demonstrate that you have spent substantial effort on this project, and you will thus likely receive partial credit for the performance score.
In accordance with the course grading policy, your assignment should not have any identifiable information on it, including your Banner ID, name, or cslogin.
cs146_handin chatbot to submit all contents in your current directory as a handin. This directory should contain all relevant files, but for the sake of space, do not include the dataset in your handin. In addition to the Python scripts, include your README and saved model. You should include your model as a link to Google Drive or Dropbox. In your README, please note down:
- The url of the training and testing comet.ml record,
- The link to your saved model,
- A brief description talking about your rationale behind the hyperparameters used,
- Your perplexity scores for the finetuned GPT-2 model,
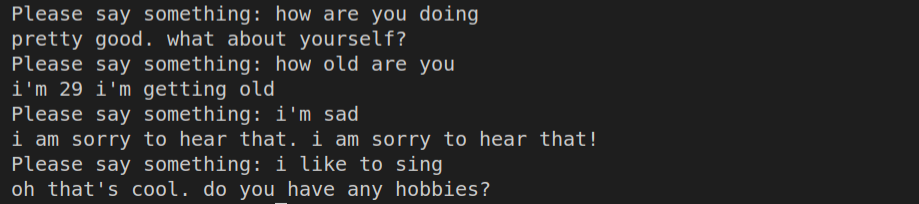
- Sample conversation you had with the chatbot,
- Other ways to improve the current chatbot given the persona dataset.
As a sanity check, the model should have less than perplexity of 100. But if you
If you were unable to get good results from the models developed, further write down in your README:
- How have you verified that the data preprocessing (i.e. the input and labels) is correct (including how you masked the data)?
- How have you verified that the problem does not lie in the model? (Can you argue, with references, that your model exactly follows the transformer model? What lines correspond to which part of the model?)
- How have you verified that it isn't just a simple hyperparameter issue? (Have you tried experimenting with them? Do you have a report / table / chart demonstrating that you have comprehensively searched the space, yet still unable to reach the target score?)
Going through these steps should hopefully help you identify the potential issues in your code, if any. Even if you were unable to find the issue in time, the report that you have created at this point would demonstrate that you have spent substantial effort on this project, and you will thus likely receive partial credit for the performance score.
In accordance with the course grading policy, your assignment should not have any identifiable information on it, including your Banner ID, name, or cslogin.