WebView is a visualization of how the web is currently being used. It is designed to monitor the web sites that are currently being browsed and to accumulate this information by category into a meaningful (and interesting) display. At the same time, it is a demonstration of the potential of the TAIGA programming system.
To make this visualization interesting and effective, we need to have people using it. Thus we encourage you to download, install and run the software.
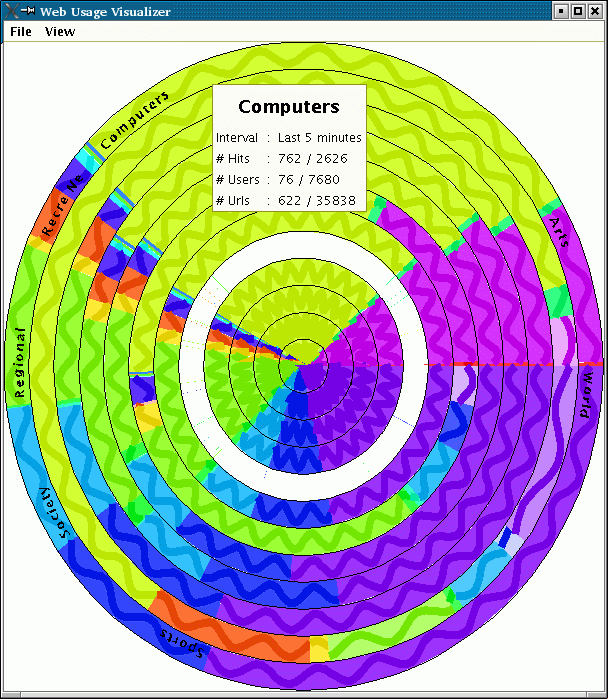
From the users' point of view, webview is a simple script that puts up a categorized display of what people are currently browsing. A sample display is shown below:
The display consists of concentric rings, each of which represents a time period ranging from one minute to several days. Each ring is divided into regions reflecting a single category of web pages. (We currently use the OpenDirectory classification, but any categorization would work). The categories are arranged alphabetically, going around counterclockwise from the 3 o'clock position (which makes sense for mathematicians at least). Colors are arbitrary, but are chosen to maximize the difference between possibly adjacent categories. Within each category area is a wavy line that encodes information about the the pages being viewed in that category. The display is updated every minute or so.
The display provides the user with several types of information. The arc span for each category is proportional to the number of views (pages requested by a browser) of pages of that category during the time span. The hue of the region denotes the category; the saturation of the coloring reflects the relative number of views. Thus, if a span has relatively few views (where relative is based on the amount of time covered by the span versus the overall history), then the region will be lighter; if the span has a lot of views, the span will be darker. The wavy line itself can encodes the relative number of distinct URLs during the time span in the frequence of the line. Thus, if all the pages viewed for a single category were from a single url, the line would be flat; if each was distinct, the line would be quite wavy. The thickness of the line is used to reflect the relative number of users browsing pages of that category. If all the browsing was done by a single user, the line would be quite thin; if its corresponds to lots of distinct users, the line would be thick.
The display can also encode information in the brightness (fade to black) of the spans and in the amplitude of the lines. The user has the option of changing the various display properties through appropriate dialog boxes. This includes changing the statistic associated with each graphical property, changing the colors associated with the different categories, mapping categories, and changing the different spans.
In order to display information about what is happening on the web, we need to gather the information. Thus, this program is spyware. It monitors your browsing history and reports the pages you browse to a central server where they are categorized and the categories are recorded. However, the program records no identfying or personal information. "Users" are represented by a unique random ID that is only used to get user counts. The IDs are arbitrary and can't be traced back to the source (as far as I know). The spyware only works when you are running the viewer and only for the user who does the running. Full source is provided if you don't believe what is going on.
Note that our tool works on windows, linux, and Mac OS/X with safari, mozilla, IE, and Opera in various combinations. If you want to contribute to the project data but don't want to run the visualizer, we provide a script which runs only the history monitor.
The system never saves URLs or user ids. Instead, as it learns about a page, it finds the appropriate category and periodically saves information about the number of pages, users and URLs for each category. The system does not download or access a page in order to find its category. Instead, it attempts to find the category only using the URL.
Using the TAIGA framework, we allow multiple implementations of classifiers. We currently provide three different ones. Our first categorizer used the Google web service, asking Google to search for the particular page and looking at the Open Directory classification that Google returns as part of the result. This is limited both because Google doesn't want us to call the web service more than 1000 times a day and because they don't always report the classification even for relatively common pages. An alternative is the MeURLin project. We have a classifier that talks to their demonstration web page (they don't have a web service set up yet), and extracts the result. This is quite effective (with varying degrees of accuracy), but is still a bit too slow for our purposes. Our third classifier reads the open directory database at start up and builds a classification tree for a URL. Once the tree is built (which takes 15 minutes and 2G of memory), the lookup is quite fast. While all three classifiers are available, and TAIGA is free to choose whichever is best at a given time, the most likely one being used right now is the latter.
If anyone has a better classifier or one that they would like to try, I would be happy to quickly integrate it into the system. Taiga allows the implementation to be a library, client-server type service, or web-service.
We are using the global file system properties of TAIGA to provide the initial information repository. The accumulated results from information gathering are periodically appended to a current data file. Because this file can potentially get rather large, we actually maintain a set of data files where files are linked from one to another. A separate server is provided to identify the current file for a given starting time, to create new files as the data files get too large, and to link the files to one another. This service will be started automatically (if it isn't already running) on a machine at Brown.
At the heart of this project is the TAIGA system. When you run the visualizer, you will also be running the TAIGA kernel on your machine. Taiga uses the JXTA peer-to-peer package to provide communication among the various kernels and services. At initial startup you will probably see (at least for now) a JXTA configuration dialog box. If things are working, just clicking okay should be sufficient. If you are familiar with jxta, feel free to modify the various settings. Using JXTA, webview should be able to run inside firewalls and on arbitray machines. If you want to get a log from the TAIGA kernel as it runs on your machine either set the environment variable TAIGASHOW (on windows) or set the environment variable TAIGALOG to the full pathname of an appropriate log file.
Nothing has been written about this project yet. We value any experiences you have with it and welcome any and all feedback for when (and if) we do write a report.
This software is (very) experimental. We have attempted to do a variety of different installations, but have only a limited range of systems available. There is a lot that can go wrong both in the kernel, in the application, and in the networking that glues everything together. We want to fix things, but to do so we need to know what doesn't work (and possibly what does). We welcome all feedback, bug reports, suggestions, comments, inquiries, etc. Send email to spr@cs.brown.edu.
If you are in Brown computer science, the latest release of the software can be obtained at /home/spr/tryview (Y:\home\spr\tryview on windows).
If you are outside of the Brown CS network, the software can be obtained from our ftp server in either (tar.gz) or (zip) format.
Installation is simple: download and expand the software. Running it is simple as well: simple execute the runview script (or runview.bat on windows) to get the visualizer.(To run only the monitoring software use the runspy scripts).
Again. To download the softare:
DOWNLOAD webview.distrib.tar.gz
DOWNLOAD webview.distrib.zip