Data Structures and Algorithms
Imagine you have an n-ary tree which you wish to modify. For instance, the tree might represent the HTML of a Web page which you intend to change dynamically.
The simplest way to update the tree would be to copy it, incorporating the change while copying. Copying, however, takes time and space proportional to the size of the tree. If we wish to make several edits that are within close proximity of each other, perhaps we can devise a representation with lower complexity. Furthermore, we might wish to make these edits atomically, i.e., so the client sees only the result of all the edits and not the intermediate stages.
We can therefore consider representing trees in terms of a cursor, which reflects the locus around which we wish to modify the tree:
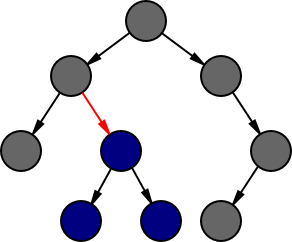
A cursor represents an edge (shown in red) and has two parts: a representation of the (possibly empty) tree below that edge (shown in blue), and the (possibly empty) rest of the tree around that edge (shown in grey). The simplest representation of the part below is the subtree itself, but we have some choices in how we represent the rest of the tree, depending on which operations we wish to support.
We will represent a tree as follows:
(define-type (Tree 'a) [mt] [node (value : 'a) (kids : (listof (Tree 'a)))])
We wish to support the following operations:
(find [tree : (Tree 'a)] [proc : ('a -> boolean)]) : (optionof (Cursor 'a))
This constructs a cursor by finding a point in a tree. The cursor
represents the edge above the first node with a value for which the
predicate produces true. We will assume that the search
proceeds depth-first (so the cursor represents the edge above the
leftmost node matching the predicate, and if there are multiple such nodes,
it represents the edge above the topmost one).
If the item you are looking for does not exist in the tree, you will
optionally return nothing rather than something. See the plai-typed
docs for optionof for more information on how to use optionof.
Given a cursor, we can update the sub-tree at the bottom of the edge that it represents in constant time:
(update (c : (Cursor 'a)) (proc : ((Tree 'a) -> (Tree 'a)))) : (Cursor 'a)
Note that because we have an explicit representation for an empty node, this operation can be used to insert, change, or delete a subtree. You would be wise to cover these operations in your test cases.
Once we are done performing updates, we can convert a cursor back into a tree:
(->tree (c : (Cursor 'a))) : (Tree 'a)
In the output from ->tree, mt will only be used to represent a completely empty tree (no nodes), so the tree you return shouldn't contain any mt nodes, unless the tree is empty.
Inside your cursor, however, you may use mt inside your cursor however you'd like, for example, if update is used to delete a subtree.
In addition, we can navigate around a cursor:
(left (c : (Cursor 'a))) : (Cursor 'a) (right (c : (Cursor 'a))) : (Cursor 'a) (up (c : (Cursor 'a))) : (Cursor 'a) (down (c : (Cursor 'a)) (n : number)) : (Cursor 'a)
The down operation takes a numeric argument to indicate
which child to select (with the index starting at 0).
Note that any of these operations might fail dynamically if the cursor
is at the appropriate boundary. For instance, left and
right should only be able to move between edges that share
a common parent. If an invalid move occurs, signal an error. You can use
the (error : (symbol string -> '_a)) call.
Critically, we want to make these four “motion” operations efficient—constant time or as close to it as possible. Can you design a data structure that achieves this? What is the complexity of the above operations that result from your representation choice?
We would also like you to test your code using an oracle. This oracle should generate trees, feed them to your updater, and verify the output. The presence of a working oracle should make you feel much more confident about your code.
Give a written explanation of how you designed your Cursor. Be
sure to explain why you made the choices you made and how this affected
the implementation of the various operations.
Note: It is important to make sure your analysis correctly describes your implementation. You will receive full credit on this section only for an accurate analysis of your code, even if your code is suboptimal.
Using what you will learn in class this week, do a big-O analysis of the complexity of your operations.
There's no reason to stop with only one cursor: we can generalize to
cursor sets. For instance, find can return the
set of all cursors that match the given criterion (e.g., all
the links on a Web page). In addition, sets of cursors can be
combined with the usual set-theoretic operations. In a new file,
updater-sets.rkt, extend your implementation to handle
sets of cursors, being sure to consider and handle the subtleties that arise.
A Racket file, updater.rkt, containing Plai-Typed code with your implementation of updater,
along with an oracle that tests each facet of your code.
A file, analysis.pdf with your answers for Part 3, and your big-O analysis, should you choose to complete Extra Credit 1.
If you choose to do the Extra Credit 2, a file, updater-sets.rkt, containing your implementation of cursor sets.
Your analysis must be in a pdf file on Letter-sized paper. Mathematical content
must be formatted appropriately. Please, no Arial.