Steven P. Reiss
RESEARCH
Integrated Development Enviroments and Tools
Overview
Programming is a difficult task. The goal of a programming environment is to provide tools that help the programmer and simplify the task. We are a strong proponent of programming tools and have been developing such tools for a long time. While an undergraduate, I worked on the Dartmouth Basic runtime system. One of the key innovations here was to add a source-language debugger to the environment.
I do a lot of programming. As such I appreciate having the best and most efficient and practical programming tools. Much of my research has been devoted to this end. This page describes some of the projects we have undertaken. This work has been funded by a variety of grants from the NSF and DARPA as well as industrial funding from Sun, Google, and Microsoft.
1. Pecan
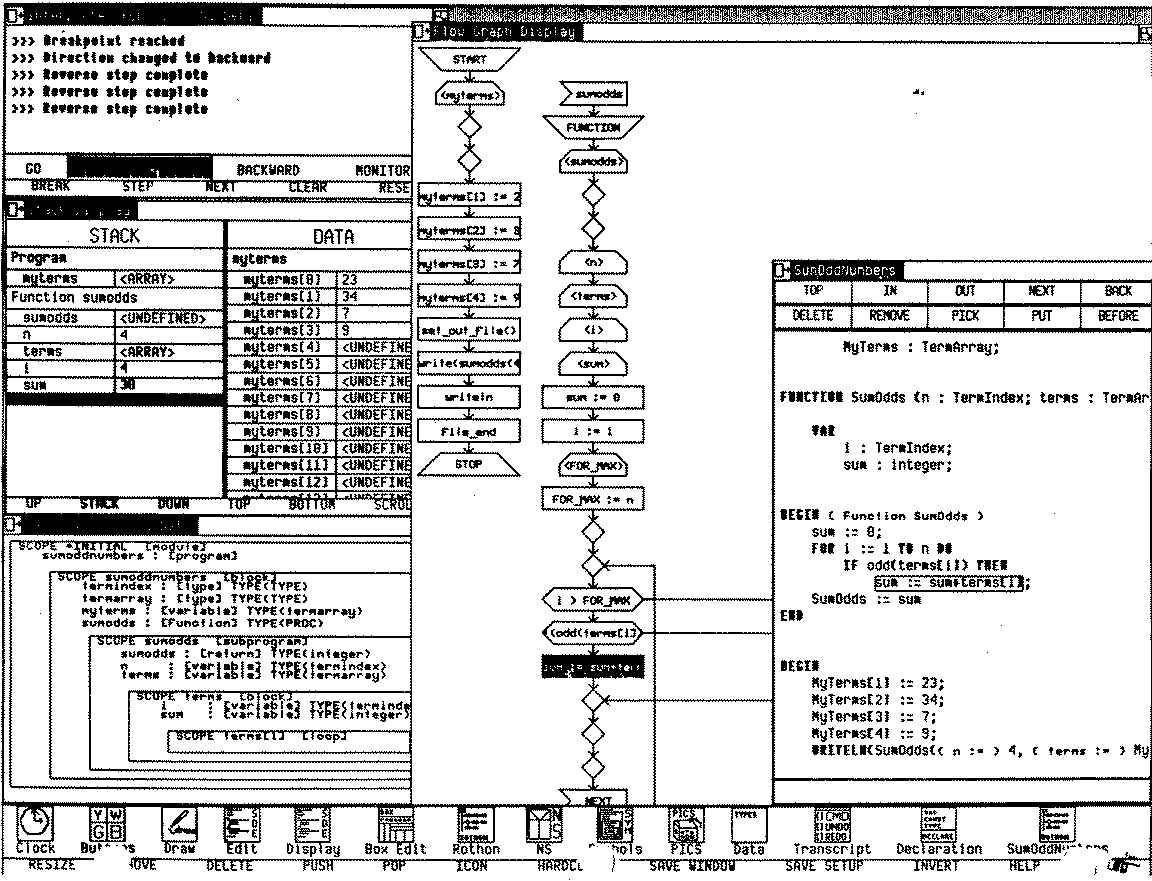
Our real research in programming environments started with the advent of workstations (Apollos, Suns, Percs, ...). We (along with several other groups) felt that one should be able to make use of the additional computational power and the graphics display to simplify and enhance the programming experience. Our initial attempt here is reflected in the PECAN system. PECAN used compiler technology to generate a tool suite for a language. The tool suite included textual (partially syntax-directed) and graphical (Nassi-Schneiderman diagrams, Rothon diagrams) editors, semantics views of the symbol table, control flow, and expressions, and execution views of the stack and the code. It also featured incremental compilation as the user typed.
PECAN was a precurser of modern IDEs in many ways. It featured multiple views similar to todays. It offered compiler feedback as the user typed. It included features such as reverse execution that have become more common in the last decades. However, while it was fun and taught us a lot, it was not practical. Machines today are 1000 times faster with 1000 times the memory. PECAN was a bit sluggish and ran out of memory at around 1000 lines of code. It also was very text oriented and, being new to workstations, we thougt that something more graphical might be more effective.
Resources
2. Garden
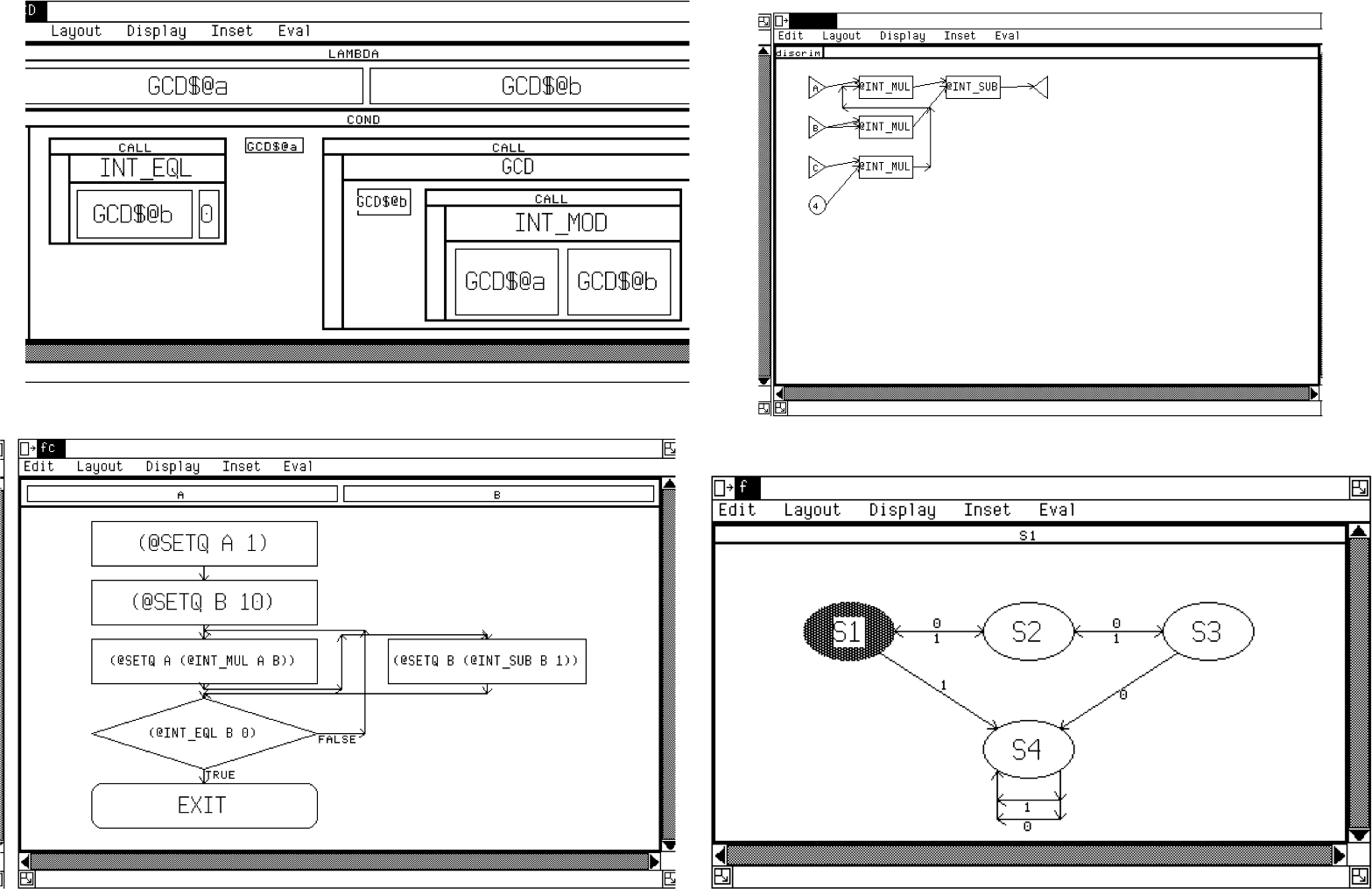
Based on this work, we next tried to make better use of the graphical capabilities of workstations by using visual languages. We realized that visual languages usually only cover a limited part of programming (e.g. only control flow or only data flow), and that to do real programming we would have to let the programmer work with multiple such languages. To accomplish this we developed what we called a conceptual programming environment, GARDEN, that let the programmer develop new visual or textual languages (with appropriate visual syntax and appropriate semantics), and nest and otherwise intermix these languages in a full system. The system provided appropriate graphical and textual editors, a Lisp-like base language, a full shared object store (to let multiple programmers work on the same program at once and to support distributed applications), Smalltalk-like browsers, multiple threads, and even a compiler. The system was used to develop a wide variety of visual languages.
GARDEN included several unique features. It was built on top of a permanent object store that supported dynamic classes and treated fields and methods similarly as in modern JavaScript. These objects could be display either textually or graphically (hence graphical languages) and could be executed directly (hence direct execution of diagrams which were composed of objects). Execution could be visualized as highlighting of objects as they were triggered. The GARDEN notion of conceptual programming can be seen in Microsoft's intential programming efforts decades later. GARDEN itself proved difficult to use and wasn't fast enough to be practical. While it was a nice tool for experimentation, it wasn't an environment we (or anyone else) wanted to develop in.
Resources
3. FIELD
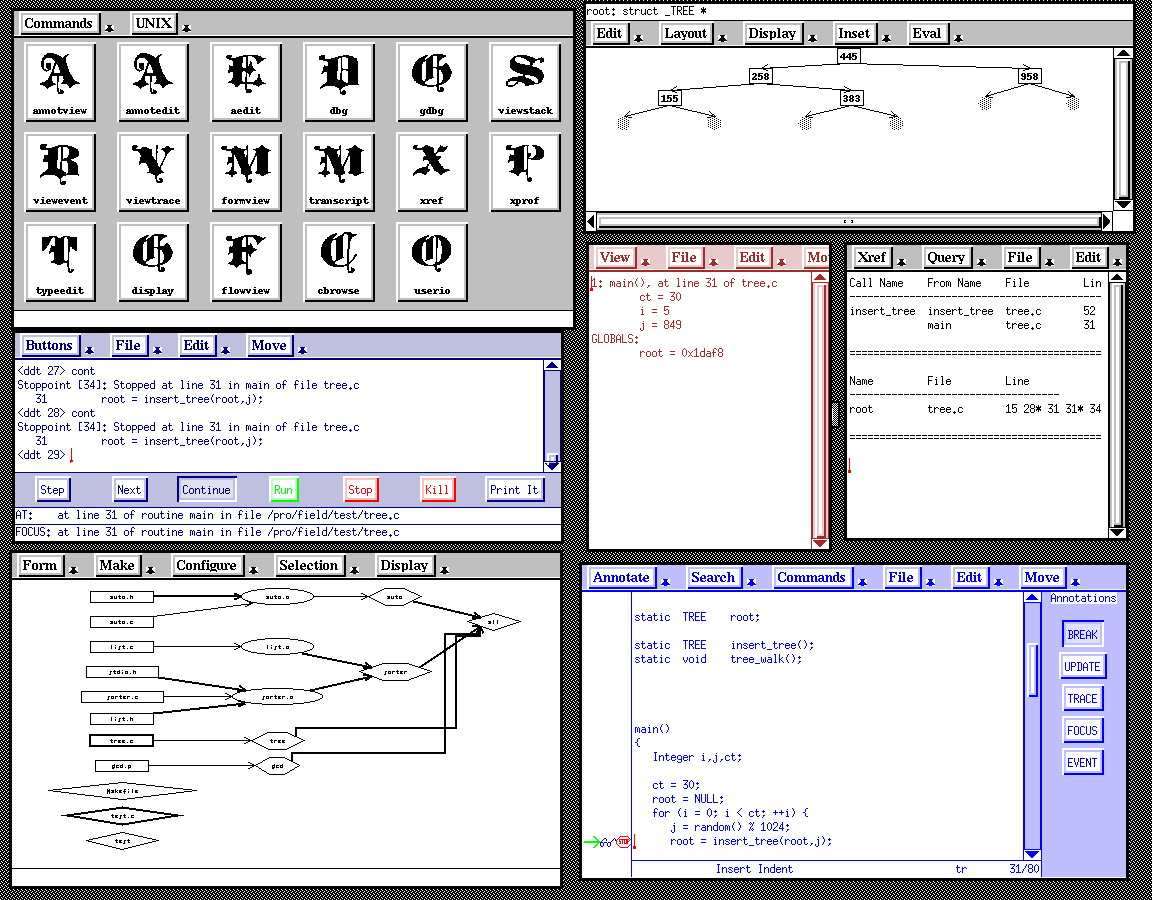
While developing GARDEN, several people challenged the overall research in programming environments, claiming that while the tools that we and others were developing were nice and might be useful, nothing was actually practical and none of the projects could really use themselves for development; everyday development of programs on UNIX (or any other OS at that time) was done using separate and textual editors, debuggers, etc. that hadn't changed significantly in ten years. We thus started developing a practical environment for real programming. We realized that you didn't need to have a common store or central representation to have an integrated environment, nor did you need to develop new tools to have graphical front ends. Instead we developed a simple message-based integration mechanism that let tools talk to one another, and a series of wrappers that provided graphical interfaces to existing tools (dbx, gdb, make, rcs, ...). The result was the FIELD environment. As it was developed, we extended the environment with a variety of graphical views including structural views (flow chart, class hierarchy), and dynamic views (data structure displays, heap vizualization, I/O visualizations). FIELD was quite successful. We used it for several years in our intro programming courses, it was commercialized by DEC (as FUSE), and was copied by HP (Softbench), Sun (Tooltalk), SGI, and others.
FIELD pioneered several concepts. It was the first system (we know of) to use a central message server and with broadcast messages being sent based on registered patterns. This approach was widely used in Corba and other message based frameworks such as todays Robot operating system (ROS). It used common editors with annotations for editing, debugging, and showing context for other tools such as search. It integrated the available configuration management systems into the environment. These concepts and some of the visualizations are used in our current environments.
Resources
4. DESERT
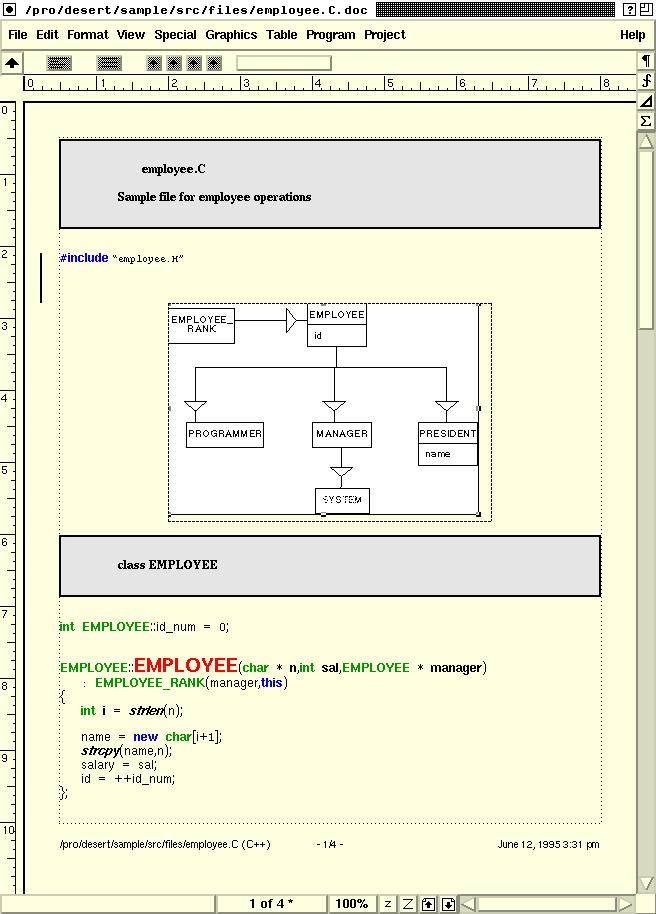
Our next environment, DESERT, tried to extend FIELD in several ways. First, it wanted to provide the programmer with a high-quality display of the code. This was done by extending Adobe Framemaker as a program editor. The extension featured Baeker-Marcus style code formatting that was done as the user typed which included semantic lookup of symbols over the whole system (and not just the current file). Second, we wanted to let the programmer view the system in different ways, being able to isolate the code relevant to a particular change or feature. This was done by splitting the program into fragments and having each editor work on virtual files consisting of different fragments gathered from actual source files. The programmer could specify a set of fragements using appropriate queries. Fragments were under configuration management and changes made to the virtual files were integrated into the original source files when the virtual files were saved. Finally, DESERT included a visualization framework, CACTI, that integrated into the system.
Basing DESERT on FrameMaker was novel, but it imposed too much overhead and was not particularly practical. Moreover, the system wasn't as integrated as we would have liked since many of the tools (e.g. the visualizations, quering fragments, configuration management) were done outside of FrameMaker. The formatting looked good, but didn't seem to contribute that much to actually working on or editing the code. What we did like from the system was the ability to create files containing all the code relevant to a particular task, putting this all in one place. This was reinforced in our later Code Bubbles system.
Resources
5. CLIME
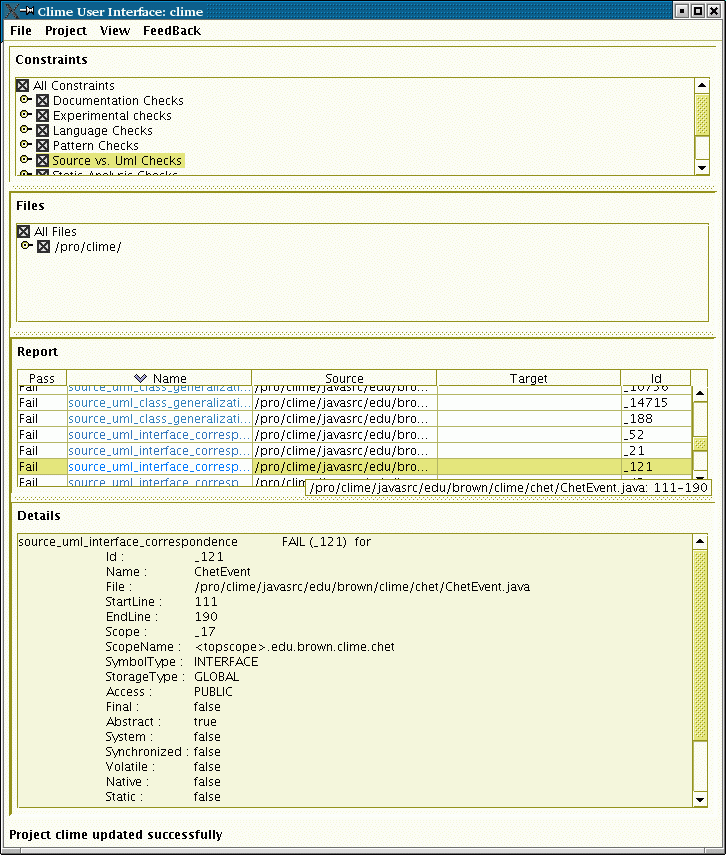
Our next effort concentrated on providing support for evolution and software consistency rather than attempting to provide a comprehensive programming environment. This package, CLIME, assumes there are tools for creating and maintaining all the different artifacts that accompany a software system: the specifications, design, source, test cases, documentation, etc. The semantics of each of these artifacts is then defined in terms of a set of metaconstraints with respect to the other artifacts. The design is viewed as contraints on the source (and vice versa) so that a class in a UML diagram has to have a corresponding class in the source; language usage rules constrain the form of the source; documentation must be consistent with the code; test cases must cover the code and be rerun as the code changes. All this is checked incrementally as the use edits the artifacts and any resulting inconsistencies are displayed using a graphical interface.
While CLIME concentrates on the static structure of the source and the various software artifacts, we realized that some of the specifications and design artifacts related to the behavior of the application rather than the code itself. To accommodate this, we have been developing CHET, a tool for checking class and library specifications in real software systems. CHET can take input based on a extended automata over events (which can be derived from UML interaction diagrams, class contracts, etc.), find all instances of the specification in a large system, and then check each instance.
While the ideas behind CLIME were correct, the implementation was a bit clumsy and not accurate or detailed enough to be practical. The analysis of UML and documentation, for example, did not capture enough information to tell if it matched the source in anything but a cursory way. The flow analysis done by CHET was useful and fast, but the specification of safety conditions was difficult. We hope to eventually integrate the consistency checking concepts from CHET into a real environment. We have recently taken the basics of the flow analysis and integrated it into Code Bubbles so that flow analysis is performed as the user types.
Resources
- Paper: Incremental Maintenance of Software Artifacts
- Paper: Specifying and Checking Component Usage
- Software: clime.tar.gz
6. CODE BUBBLES
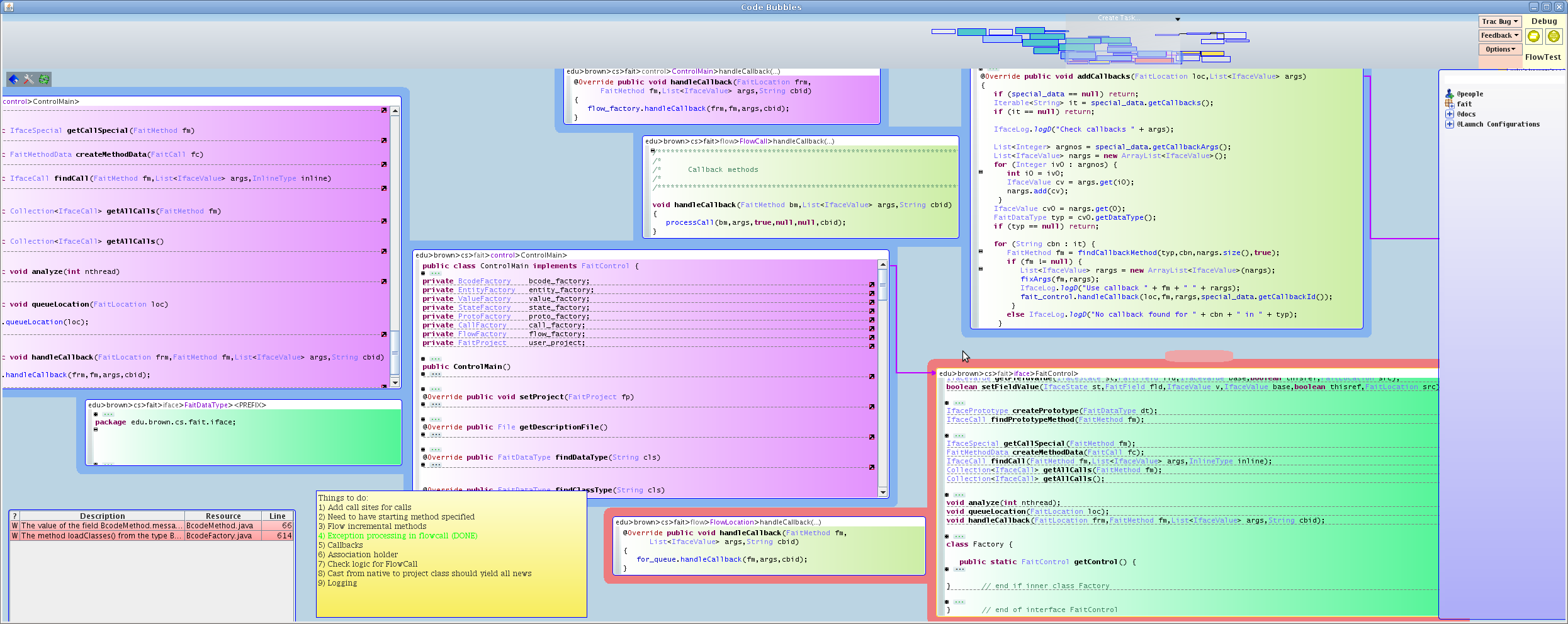
These different experiences led us to our current development environment, Code Bubbles. Code Bubbles was a rethink of the user interface for development that focused on working sets, the set of software artifacts needed to handle a specific task, developed by Andrew Bragdon when he was a Ph.D. student. The working set notion is similar to that of the fragments in the Desert enviroment. The underlying system is composed of multiple communicating components using a central message server as in the Field enviroment. The code formating is a simplified version of what was used in Desert. Code Bubbles also features a number of visualizations, both of the static structure and of program dynamics.
Code Bubbles is a full-featured environment, offering tools for writing code, editing, debugging, searching, configuration management, and visualization, as well as plug-ins for UML. It is currently being used for its own development as well as a wide variety of other projects. It is available both as source code and as an open source project.
Code Bubbles has been a vehicle for research into new and advanced programming tools and environments. It contains interfaces to our code search tool S6, an interface for exploring code repositories, automatic dynamic visualizations, a show and tell help system, live programming for Java, automatic repair of syntactic errors, change notification, and checking safety conditions as the user types.
The environment currently sits on top of Eclipse, but we expect to port it to use IntelliJ as an alternative back end in the next year or so. Anyone interested in using or working on the system should look at the Code Bubbles web pages or contact Steven Reiss.
Resources
- Paper: "Code Bubbles: Rethinking the User Interface Paradigm of Integrated Development Environments"
- Early Video: Bubbles Help Demo
- Video: Code Bubbles Visualizations
- Software: GitHub Repository
DYMON
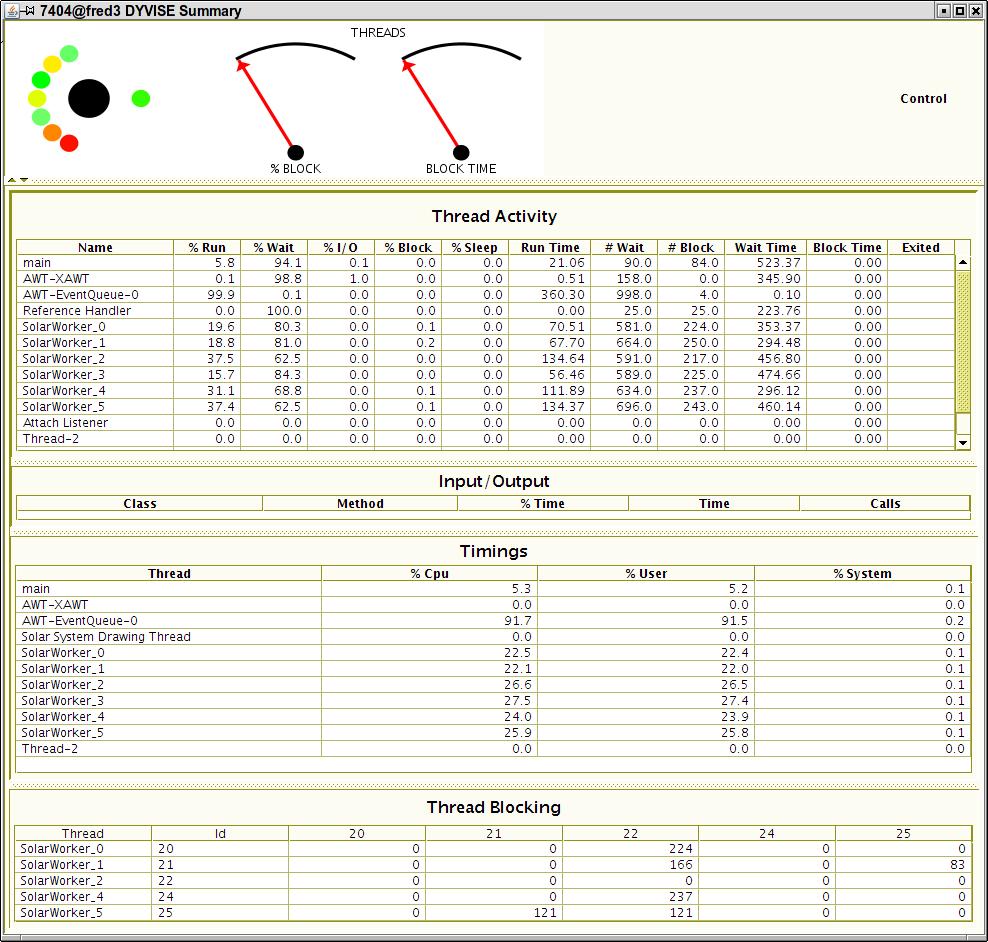
DYMON is a collection of tools for monitoring the behavior of Java programs as they run. It is designed so it can be dynamically attached to a running program and generates a variety of performance information about the program with very low, user-settable, overhead. The tools include DYVISE for general performance, DYMEM for understanding memory usage and ownership, and DYLOCK for understanding locking behavior.
SEEDE
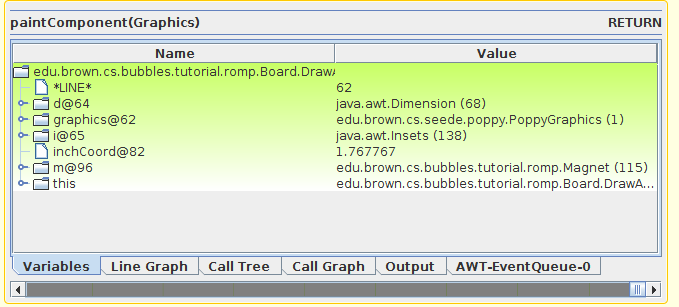
SEEDE is a tool for doing live programming in real Java systems. It assumes that the user has stopped at the start of method within the debugger. It then virtually interprets the code in that method and anything it calls, updating as the user types, and providing a complete history of the execution including all variables, graphics, and file I/O. The user can browse this historyusing a time slide. Graphical output is shown for any affected widget.
Resources
FAIT

FAIT is a tool for doing security checking during development. It does an abstract interpretation-based flow analysis of the complete system under development and updates this analysis (incrementally) as the user types so it is always up-to-date. The user can specify the security conditions that need to be checked in their system and the current state of these checks is reported immediately. FAIT handles most aspects of real systems, including most native calls, uses of reflection, and the intricacies of the Java libraries.
Resources
- Paper: Continuous Flow Analysis to Detect Security Problems
- Software: GitHub Repository
ROSE
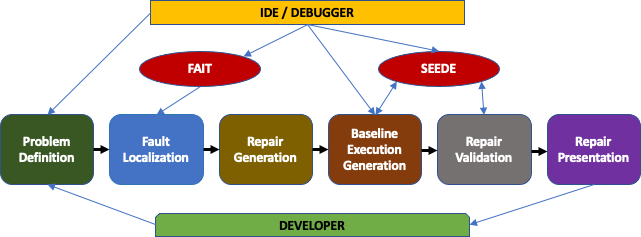
ROSE is a tool for doing practical automatic bug repair, essentially a QuickFix for semantic errors while debugging. ROSE can be invoked at any stopping point during execution where the developer has detected a symptom that something is wrong. This can be an exception that is thrown, an assertion that is violated, a variable that has the wrong value, or the fact that execution should not have gotten to this point. ROSE has the developer quickly describe the symptom, then does a fast generate and validate automatic program repair (APR). Unlike existing APR systems, it does not depend on a test suite or even a test case. It does fault localization using FAIT to identify possible locations relevant to the symptom restricted by the current execution environment. It then uses a set of possible patch generators based on patterns, code search, and machine learning to quickly generate potential patches. It validates these patches by comparing executions generated by SEEDE for the original and the patched code. It can find viable suggestions for fixing the problem in well under a minute even for complex systems.
Resources
- Paper: A Quick Repair Facility for Debugging
- Paper: ROSE: An IDE-Based Interactive Repair Framework for Debugging
- Video: ROSE demonstration
- Software: GitHub Repository